
📚 CPU 스케줄링 알고리즘
✅ 도입
- 이전 포스팅 프로세스 스케줄링 을 통해, 프로세스 스케줄링을 이해하고 왜 필요 한지에 대해 알아 보았다.
- 이번에는 대표적인 스케줄링 알고리즘을 Java 코드와 함께 소개하고, 리눅스 운영체제의 CPU 스케줄링에 대해서 알아보자.
- 선점형과 비선점형 스케줄링
📌 예제 코드 소개
- Java로 다양한 스케줄링을 소개할 것이기 때문에, 먼저 프로세스&스레드 작업을 나타낼
Job클래스를 다음과 같이 정의해 주겠다.
public class Job {
private final String name;
private final int arrivalTime;
private final int burstTime;
private int remainingTime;
public Job(String name, int arrivalTime, int burstTime) {
this.name = name;
this.arrivalTime = arrivalTime;
this.burstTime = burstTime;
this.remainingTime = burstTime;
}
public String getName() { return name; }
public int getArrivalTime() { return arrivalTime; }
public int getBurstTime() { return burstTime; }
public int getRemainingTime() { return remainingTime; }
public void decRemain() { this.remainingTime--; }
}✅ 비 선점형 계열
- 비 선점형은, 한번 실행된 프로세스는 외부에 의해서 CPU 할당을 뺏을 수 없는 알고리즘 이다.
- 대표적으로,
FCFS,SJF,HRD등이 존재한다. - 그 중,
FCFS와SJF에 대해서 간략하게 소개한다.
📌FCFS (First Come First Served)
- 이름 그대로, 먼저 오는것을 먼저 서빙한다.
- 즉, 해당 알고리즘에서 CPU의 자원을 할당할
우선순위는 들어온 순서 이다. - 오는 순서대로,
Queue에 쌓고, 들어온 순서대로poll하여 작업을 수행한다.
public class FCFSScheduler {
public static void main(String[] args) {
Queue<Job> jobQueue = new LinkedList<>();
jobQueue.offer(new Job("A", 0, 3));
jobQueue.offer(new Job("B", 2, 6));
jobQueue.offer(new Job("C", 4, 4));
jobQueue.offer(new Job("D", 6, 5));
jobQueue.offer(new Job("E", 8, 2));
int currentTime = 0;
System.out.println("순서\t도착\t실행\t시작\t종료");
while (!jobQueue.isEmpty()) {
Job job = jobQueue.poll();
int startTime = Math.max(currentTime, job.getArrivalTime());
int endTime = startTime + job.getBurstTime();
System.out.printf("%s\t%d\t%d\t%d\t%d\n",
job.getName(), job.getArrivalTime(), job.getBurstTime(), startTime, endTime);
currentTime = endTime;
}
}
}- 결과
| 순서 | 도착 | 실행 | 시작 | 종료 |
|---|---|---|---|---|
| A | 0 | 3 | 0 | 3 |
| B | 2 | 6 | 3 | 9 |
| C | 4 | 4 | 9 | 13 |
| D | 6 | 5 | 13 | 18 |
| E | 8 | 2 | 18 | 20 |
- FCFS 는, 구현이 매우 단순하고 공정성이 있는 알고리즘 이다.
- 하지만, 긴 작업이 먼저 들어오게 되면, 뒤에 있는 짧은 작업이 오래 기다려야 되서 응답 시간이 느려질 수 있다. (호위 효과)
호위 효과란? (Convoy Effect) CPU 버스트가 긴 프로세스가 앞에 있으면, 그 뒤의 짧은 프로세스/입출력 집중 프로세스들이 모두 함께 길게 대기하게 되는 현상을 의미한다. 긴 작업 하나 때문에 전체 시스템 처리 효율이 떨어질 수 있다. 대표적인 FCFS의 단점 중 하나!
📌 SJF (Shortest Job First)
SJF는, CPU를 이용하는 시간의 길이가 가장 짧은 프로세스 부터 먼저 실행하는 스케줄링 방식이다.- 즉,
CPU 버스트시간이 가장 긴게 먼저 할당을 받아 실행되게 된다. - 우선 순위가 들어온 순서가 아니기 때문에,
호위 효과문제가 발생하지 않는 장점이 있다.
public class SJFScheduler {
public static void main(String[] args) {
List<Job> jobs = Arrays.asList(
new Job("A", 0, 3),
new Job("B", 2, 6),
new Job("C", 4, 4),
new Job("D", 6, 5),
new Job("E", 8, 2)
);
// 도착 시간 순으로 미리 정렬
jobs.sort(Comparator.comparingInt(Job::getArrivalTime));
int currentTime = 0;
int completedJobs = 0;
int totalJobs = jobs.size();
// SJF는 도착한 Job들 중 burstTime이 가장 짧은 것을 선택해야 하므로, PQ를 사용
PriorityQueue<Job> readyQueue = new PriorityQueue<>(Comparator.comparingInt(Job::getBurstTime));
System.out.printf("%-5s %-6s %-6s %-6s %-6s%n", "순서", "도착", "실행", "시작", "종료");
int idx = 0; // 아직 readyQueue에 넣지 않은 jobs의 인덱스
while (completedJobs < totalJobs) {
// 현재 시점까지 도착한 Job들은 모두 readyQueue에 넣기
while (idx < totalJobs && jobs.get(idx).getArrivalTime() <= currentTime) {
readyQueue.offer(jobs.get(idx));
idx++;
}
// readyQueue가 비어있으면, 다음 Job이 도착할 때까지 currentTime을 미루기
if (readyQueue.isEmpty()) {
currentTime = jobs.get(idx).getArrivalTime();
continue;
}
// burstTime이 가장 짧은 Job 꺼내 실행
Job job = readyQueue.poll();
int startTime = Math.max(currentTime, job.getArrivalTime());
int endTime = startTime + job.getBurstTime();
System.out.printf("%-5s %-6d %-6d %-6d %-6d%n",
job.getName(), job.getArrivalTime(), job.getBurstTime(), startTime, endTime);
currentTime = endTime;
completedJobs++;
}
}
}| 순서 | 도착 | 실행 | 시작 | 종료 |
|---|---|---|---|---|
| A | 0 | 3 | 0 | 3 |
| B | 2 | 6 | 3 | 9 |
| E | 8 | 2 | 9 | 11 |
| C | 4 | 4 | 11 | 15 |
| D | 6 | 5 | 15 | 20 |
FCFS와 달리, 실행 순서가 조금 변경된 것을 확인할 수 있다.SFJ는, 기본적으로 비선점형 스케줄링 알고리즘으로 분류되지만,최소 잔여 시간 우선 스케줄링처럼 선점형으로 구현될 수도 있다.
✅ 선점형 계열
- 선점형은, 한번 실행된 프로세스는 외부에 의해서 CPU 할당을 뺏어오는 알고리즘 이다.
- 대표적으로,
RR,SRT,Prioirty,MLQ등이 존재한다.
📌 RR (round robin)
- 라운드 로빈 스케줄링은, 선입 선처리 스케줄링(
FCFS)에, 타임 슬라이스라는 개념이 더해진 스케줄링 방식이다. 타임 슬라이스는, 프로세스가 CPU를 사용하도록 정해진 시간을 의미한다.- 즉, RR 전략에서 프로세스는 CPU 할당을 받아 연산을 실행하다가
타임 슬라이스시간이 되면 현재 상태를 저장하고 할당 받은 자원을 포기한다. - 그리고, 완료가 다 안된 작업은 다시
준비큐에 들어가 다음 CPU 할당을 받기를 대기한다.
실제로, 현재 실행된 상태를 PCB에 저장하고 해당 부분부터 다시 로드하는 컨텍스트 스위칭 동작은 구현되어 있지 않습니다.
public class RRScheduler {
public static void main(String[] args) {
List<Job> jobs = Arrays.asList(
new Job("A", 0, 3),
new Job("B", 2, 6),
new Job("C", 4, 4),
new Job("D", 6, 5),
new Job("E", 8, 2)
);
int timeQuantum = 2; // 타임 슬라이스
jobs.sort(Comparator.comparingInt(Job::getArrivalTime));
Queue<Job> readyQueue = new LinkedList<>();
int currentTime = 0;
int idx = 0;
int totalJobs = jobs.size();
int[] remainingTime = new int[totalJobs];
for (int i = 0; i < totalJobs; i++) remainingTime[i] = jobs.get(i).getBurstTime();
boolean[] isFinished = new boolean[totalJobs];
// 각 Job 실행 시작/종료 시간 기록
int[] startTimes = new int[totalJobs];
Arrays.fill(startTimes, -1); // 아직 실행 안된 경우 -1
// 로깅용 리스트
List<String> logs = new ArrayList<>();
while (true) {
while (idx < totalJobs && jobs.get(idx).getArrivalTime() <= currentTime) {
readyQueue.offer(jobs.get(idx));
idx++;
}
if (readyQueue.isEmpty()) {
if (idx < totalJobs) {
currentTime = jobs.get(idx).getArrivalTime();
continue;
} else {
break;
}
}
Job job = readyQueue.poll();
int jobIdx = jobs.indexOf(job);
// 최초 실행시점 기록
if (startTimes[jobIdx] == -1)
startTimes[jobIdx] = Math.max(currentTime, job.getArrivalTime());
int execTime = Math.min(timeQuantum, remainingTime[jobIdx]);
int execStart = Math.max(currentTime, job.getArrivalTime());
int execEnd = execStart + execTime;
// 로그 남기기
logs.add(String.format(
"[%d~%d] %s 실행 (남은 시간: %d → %d)",
execStart, execEnd, job.getName(), remainingTime[jobIdx], remainingTime[jobIdx] - execTime
));
remainingTime[jobIdx] -= execTime;
currentTime = execEnd;
while (idx < totalJobs && jobs.get(idx).getArrivalTime() <= currentTime) {
readyQueue.offer(jobs.get(idx));
idx++;
}
if (remainingTime[jobIdx] > 0) {
readyQueue.offer(job);
} else if (!isFinished[jobIdx]) {
isFinished[jobIdx] = true;
logs.add(String.format("→ %s 종료 (총 소요: %d초)", job.getName(), currentTime - job.getArrivalTime()));
}
}
// 로그 출력
System.out.println("=== 라운드 로빈 실행 로그 ===");
for (String log : logs) {
System.out.println(log);
}
}
}=== 라운드 로빈 실행 로그 ===
[0~2] A 실행 (남은 시간: 3 → 1)
[2~4] B 실행 (남은 시간: 6 → 4)
[4~5] A 실행 (남은 시간: 1 → 0)
→ A 종료 (총 소요: 5초)
[5~7] C 실행 (남은 시간: 4 → 2)
[7~9] B 실행 (남은 시간: 4 → 2)
[9~11] D 실행 (남은 시간: 5 → 3)
[11~13] C 실행 (남은 시간: 2 → 0)
→ C 종료 (총 소요: 9초)
[13~15] E 실행 (남은 시간: 2 → 0)
→ E 종료 (총 소요: 7초)
[15~17] B 실행 (남은 시간: 2 → 0)
→ B 종료 (총 소요: 15초)
[17~19] D 실행 (남은 시간: 3 → 1)
[19~20] D 실행 (남은 시간: 1 → 0)
→ D 종료 (총 소요: 14초)
Process finished with exit code 0- 타임 슬라이스를 2로 주고, 같은 작업을 실행 하였을때 결과이다.
- 이전
비 선점형계열과 다르게, 작업들이 실행 도중 자신의 반납하고 다음 작업을 진행하는 것을 확인할 수 있다. RR은 짧은 시간 간격으로 CPU를 할당 받아 대기 시간이 길어지지 않아 응답성이 좋다.- 또한 공정하며, 기아 현상이 방지되는 특징이 있다.
- 단, 잦은 타임 슬라이스가 너무 짧으면 컨텍스트 스위칭이 자주되어 오버헤드가 발생하고, 긴 작업의 경우, 실제 처리 시간이 증가되어, 프로세스 별 평균 반환 시간이 늦어질 수도 있다.
📌 SRT (Shortest Remaining Time)
SRT는SJF을 선점 스케줄링 방식으로 변경한 기법이다.- 항상
준비큐에 있는 작업 중, CPU 처리 시간이 가장 짧은 작업을 처리한다. - 작업 중
준비큐에 짧은 버스트 타임의 작업이 들어오는 경우, 자원을 반납하여 다음 프로세스를 실행한다.
public class SRTScheduler {
public static void main(String[] args) {
List<Job> jobs = Arrays.asList(
new Job("A", 0, 3),
new Job("B", 2, 6),
new Job("C", 4, 4),
new Job("D", 6, 5),
new Job("E", 8, 2)
);
PriorityQueue<Job> pq = new PriorityQueue<>(Comparator.comparingInt(Job::getRemainingTime));
int time = 0, complete = 0, idx = 0;
int n = jobs.size();
List<String> logs = new ArrayList<>();
Map<String, Integer> startTimes = new HashMap<>();
Map<String, Integer> endTimes = new HashMap<>();
while (complete < n) {
// 도착한 Job PQ에 넣기
while (idx < n && jobs.get(idx).getArrivalTime() == time) {
pq.offer(jobs.get(idx));
idx++;
}
if (pq.isEmpty()) {
time++;
continue;
}
Job job = pq.poll();
if (!startTimes.containsKey(job.getName()))
startTimes.put(job.getName(), time);
logs.add(String.format("[%d~%d] %s 실행 (남은: %d→%d)", time, time+1, job.getName(), job.getRemainingTime(), job.getRemainingTime()-1));
job.decRemain();
time++;
// Job 끝났으면 기록, 아니면 다시 PQ에
if (job.getRemainingTime() == 0) {
endTimes.put(job.getName(), time);
logs.add(String.format("→ %s 종료 (총 소요: %d초)", job.getName(), time - job.getArrivalTime()));
complete++;
} else {
pq.offer(job);
}
}
System.out.println("=== SRT 실행 로그 ===");
for (String log : logs) System.out.println(log);
System.out.println("\n| 순서 | 도착 | 실행 | 시작 | 종료 |");
System.out.println("|:----:|:----:|:----:|:----:|:----:|");
for (Job job : jobs) {
System.out.printf("| %s | %d | %d | %d | %d |\n",
job.getName(), job.getArrivalTime(), job.getBurstTime(),
startTimes.get(job.getName()), endTimes.get(job.getName()));
}
}
}=== SRT 실행 로그 ===
[0~1] A 실행 (남은: 3→2)
[1~2] A 실행 (남은: 2→1)
[2~3] A 실행 (남은: 1→0)
→ A 종료 (총 소요: 3초)
[3~4] B 실행 (남은: 6→5)
[4~5] C 실행 (남은: 4→3)
[5~6] C 실행 (남은: 3→2)
[6~7] C 실행 (남은: 2→1)
[7~8] C 실행 (남은: 1→0)
→ C 종료 (총 소요: 4초)
[8~9] E 실행 (남은: 2→1)
[9~10] E 실행 (남은: 1→0)
→ E 종료 (총 소요: 2초)
[10~11] D 실행 (남은: 5→4)
[11~12] D 실행 (남은: 4→3)
[12~13] D 실행 (남은: 3→2)
[13~14] D 실행 (남은: 2→1)
[14~15] D 실행 (남은: 1→0)
→ D 종료 (총 소요: 9초)
[15~16] B 실행 (남은: 5→4)
[16~17] B 실행 (남은: 4→3)
[17~18] B 실행 (남은: 3→2)
[18~19] B 실행 (남은: 2→1)
[19~20] B 실행 (남은: 1→0)
→ B 종료 (총 소요: 18초)- SRT(SRTF)는 “항상 남은 실행 시간이 가장 짧은 작업”에게 CPU를 즉시 할당해 평균 대기/반환시간을 최소화하지만, 실행 시간 예측의 어려움과 긴 Job의 기아 현상, 그리고 구현 복잡성이 단점이다.
📌 우선순위 (Priority)
다음부터 소개되는 스케줄링들은 단순 코드로 표현하기에 너무 복잡하여 패스...
우선순위는 각 프로세스(Job)마다 “우선순위(Priority)” 값을 명시적으로 부여하고, 가장 높은 우선순위(숫자가 작거나 큰 쪽, OS마다 다름)의 프로세스에 CPU를 우선 할당하는 스케줄링 방식이다.- Priority 값은 OS(운영체제), 관리자, 또는 프로그램이 직접 지정한다.
- 선점형으로 소개하였지만, 선점형 / 비선점형 모두 가능하다.
- 고질적으로, 기아(아사)(starvation) 현상이 발생하게 된다.
기아 현상 프로세스가 실행 권한을 부여 받지 못하고, 계속 실행이 연기되는 현상 우선순위 방식은, 우선순위가 밀리면 지속적으로 실행이 연기되어 기아 현상이 생길 수 있다.
- 따라서,
에이징기법을 사용하여 기아 현상을 해소해줄 필요가 있다.
에이징 오랫동안 대기한 프로세스의 우선순위를 점차 높이는 방식
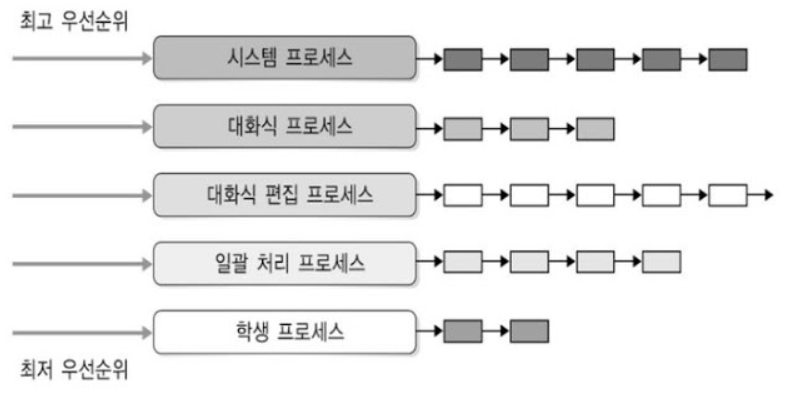
📌 다단계 큐 스케줄링 (multilevel queue) (MLQ)
다단계 큐는 우선순위 스케줄링의 발전된 형태.- 여러 개의 “큐(Queue)”를 두고, 각 큐마다 “프로세스 유형/성격”에 따라 분리해서 관리
- 예: 시스템 프로세스, 상호작용 프로세스, 배치 프로세스, 학생/교수/관리자 등)
- 각 큐는 “서로 다른 스케줄링 알고리즘”을 사용할 수 있음
- (ex: 하나는 RR, 하나는 FCFS, 또 다른 큐는 SJF 등)
- 프로세스들이 큐 사이를 이동할 수 없기 때문에, 우선순위가 낮은 프로세스의 작업이 계속해서 연기될 수 있는 단점이 있음.
- 아래 사진에서,
시스템 프로세스 큐에 작업(프로세스)가 남아 있다면, 하위 우선순위를 가진대화식 프로세스,대화식 편집 프로세스등은 실행될 수 없다. 즉 기아 현상 발생
- 아래 사진에서,
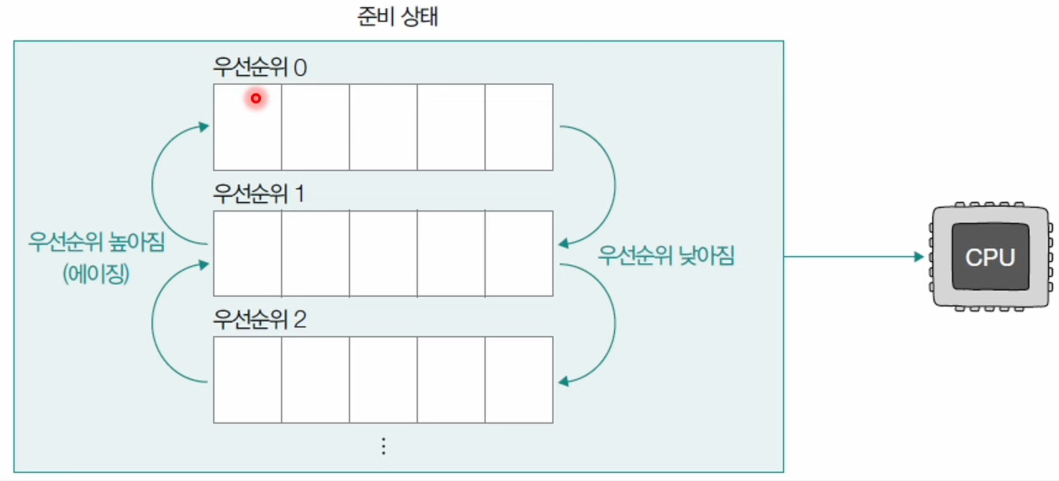
📌 다단계 피드백 큐 스케줄링 (multilevel feedback queue) (MFQ)
다단계 피드백 큐는 다단계 큐 스케줄링과 비슷하게 동작할 수 있지만, 프로세스들이 큐 사이를 이동할 수 있는 차이가 있다.- 다단계 피드백 큐 스케줄링은 다음과 같은 순서로 동작하게 된다.
- 프로세스는 먼저 우선순위가 가장 높은 우선순위 큐에 삽입
- CPU 할당을 받아 실행될 경우, 설정된
타임 슬라이스동안 실행 - 해당 큐에서 실행이 끝나지 않은 프로세스는 다음 우선순위 큐에 삽입되어 실행
- 결국, 오래 CPU를 사용해야 하는 프로세스들의 우선순위는 낮아지고, 비교적 CPU를 적게 사용해야 하는
I/O Bound작업성 프로세스들은 우선 순위가 높은 큐에서 실행이 끝나게 된다. - 또한,
기아 현상을 예방하기 위해 낮은 우선순위 큐에서 오래 기다리고 있는 프로세스들은 높은 우선순위 큐로 이동시키는 에이징 기법을 적용할 수도 있다.
✅ 리눅스 CPU 스케줄링
- 리눅스에서는 상황에 따라 다양한 스케줄링 알고리즘이 사용된다.
- 리눅스에서는 크게 5가지 스케줄링 정책을 사용하고 있다. 리눅스 커널 공식 홈페이지
- SCHED_FIFO
- SCHED_RR
- SCHED_NORMAL
- SCHED_BATCH
- SCHED_IDLE
- 이중, 가장 자주 언급되는 정책은
FIFO,RR,NORMAL이다.
📌 FIFO 와 RR
FIFO와RR은 RT(Real-Time) 스케줄러에 의해 이뤄지는 스케줄링이다.- 실시간 성이 강조된 프로세스에 적용되는 스케줄링 정책이다.
- 앞서 알아본, FCFS, Round Robbin 과 비슷한 내용이다.
📌 Normal
Normal정책은 일반적인 프로세스에 적용되는 스케줄링 정책이다.- 내부적으로
CFS(Completely Fair Scheduler)라는 CPU 스케줄러에 의해 스케줄링이 이뤄진다. CFS는 완전히 공평한 CPU 시간 배분을 지향하는 스케줄러 방식이다.- 리눅스 운영체제 에서는, 프로세스 마다
가상 실행 시간(vruntime)이라는 정보를 유지하는데,CFS는 이를 가장 작은 프로세스 부터 스케줄링 한다.
vruntime은 실제 실행 시간이 아니라, 각 프로세스의 **우선순위(nice 값)를 기반으로 계산된 가중치(weight)**를 고려한 "가상 시간"이다. nice 값이 높을수록(낮은 우선순위) → 가중치가 작아지고, vruntime이 빠르게 증가해 덜 배정됨 nice 값이 낮을수록(높은 우선순위) → 가중치가 커지고, vruntime이 천천히 증가해 더 많이 배정됨
- Normal 정책은 CFS의 이러한 원리를 바탕으로 누구도 너무 오래 기다리지 않고, 누구도 과도하게 독점하지 않게 시스템 전체적으로 "공정한 분배"를 실현한다.
📌 BATCH 와 IDLE
- 없으면 서운하니 가볍게 정리하는
Batch와Idle
- BATCH 정책은 백그라운드 일괄 처리(Batch Job)를 위한 스케줄링 정책이다.
- 일반적으로 대화형이 아닌, 대량의 계산이나 비대화형 작업(예: 데이터 처리, 로그 분석 등)에 적용
- IDLE 정책은 시스템이 한가할 때만 동작해야 하는 작업에 적용.
- 가장 낮은 우선순위를 가지며, 시스템에 CPU 여유가 있을 때만 실행된다. 보통 “CPU가 남는 시간에만 돌려도 되는” 극히 중요도가 낮은 백그라운드 태스크에 사용
- 주기적 로그 정리, 자동 백업, 저우선 배경 동기화 등